EDU
분석은 합의(合意)이다
강양석 | Deep Skill 대표
분석의 시대이다. 직관의 시대는 갔다고까지 얘기한다. 그도 그럴 것이 인공지능은 곳곳에서 인간을 넘어서는 성능을 발휘하고 있으니 말이다.그렇다면, 이 질문에도 답을 해보자.
“동일한 목적과 데이터를 가지면, 동일한 결과가 나올까?”
나름 이 질문이 중요하다고 생각하는 이유는 정말 분석이 직관을 넘어선 문제해결 능력을 가졌다면 이 질문에도 그렇다라고 얘기할 수 있어야 할 것이다. 왜냐하면 중지를 모은다는 것은 문제해결의 중요한 필요조건 중 하나이기 때문이다. 마침 이 질문에 매우 적절한 연구 사례가 있어 소개해 보겠다. 전문지식을 공유하는 비영리 단체인 센터 포 오픈 사이언스(Center for Open Science)의 설립자 브라이언 노섹(Brian Nosek)은 2015년 ‘같은 데이터, 다른 결론(Same Data, Different Conclusions)’현상에 대한 실험 결과를 발표했다. ‘축구 심판들이 흑인 선수에게 레드카드를 더 자주 준다는 말은 사실인가?’를 밝혀내려는 이 실험에는 총 29개 팀 61명의 데이터 분석가가 참여했고, 이들에겐 동일한 데이터가 제공되었다. 이들이 사용한 분석 기법들은 간단한 선형 분석에서 다중회귀 분석, 베이지안(Bayesian) 분석까지 다양했다.
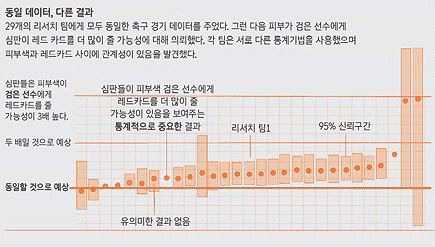
동일한 데이터로 동일한 문제에 접근해도 결과는 천양지차일 수 있다.
출처:Brian Nosek et al.
결과는 흥미로웠다. 20개 팀이 ‘흑인 선수들은 레드카드를 더 받는다’는 결론을 내린 반면 9개 팀은 ‘피부색과 레드카드는 관련이 없다’고 결론 지은 것이다. 그저 접근법이 상이했던 것일 뿐인데 말이다. 각 팀이 사용한 분석 기법은 다른 팀의 검증 절차를 거쳤기에 분석 과정에서 오류가 있을 가능성은 없었다. 분석가들의 능력 부족이나 태만이 변수였을 가능성 역시 존재하지 않았다. 또 다른 프로젝트 리더이자 저명한 심리학자인 인시아드 비즈니스 스쿨(INSEAD Business School) 아시아 캠퍼스의 에릭 루이스 율만(Eric Luis Uhlmann)이 “모든 참가자는 최고 수준의 전문가였고, 답을 찾고자 하는 열정으로 가득 차 있었습니다”라고 못박았으니 말이다. 덧붙여 그는 이렇게 갈무리했다. “하나의 분석으로 궁극의(definitive) 답을 찾는 건 쉽지 않은 일입니다. 모든 결론은 다른 결론이 그것을 뒤엎기 전까지 한시적(temporary)으로 ‘답’이라는 위치에 있을 뿐입니다.”
결국, 아무리 같은 목적과 같은 데이터를 가진 전문가들이라도 서로 다른 접근법을 취하면 충분히 다른(subjective) 결론을 내릴 수 있다는 것이다. ‘한시적인 답’이 곧 분석 무용론을 뜻하는 것은 아니다. ‘한시성’을 강조하는 이유는 분석 결과의 유연성을 인정해야 자신의 문제를 자신의 데이터로 자유자재로 해결할 용기가 생기기 때문이다. 정답과 오답이 정해져 있는 것이 아니니 용기를 가지고 더 많은 설명력을 가진, 더 오래 정답의 지위를 고수할 답을 찾아가봐야 한다는 것이다.
분석 결과에 대한 막연한 맹신은 위험
분석적인 문제해결 방법이 직관적인 분석 대비 우리의 중지를 모으고, 동일한 해결 시도에 대해 답변의 일관성을 유지시키는 것은 당연할지라도, 근본적으로 분석이 ‘답의 다양성과 변화무쌍함’을 해결해주지는 못한다. 즉, 직관과 분석 중 무엇이 우월하냐는 불필요한 질문을 넘어 분석에 대한 막연한 맹신에서 벗어나는 것이 중요하다. 그것이 진짜 분석의 힘을 기르는 시작이라고 생각하고 말이다. 그럼 분석의 정체를 다시 생각해보자. 결론부터 말하면, 분석은 ‘고도의 합의’ 행위이다. 자연과학처럼 ‘필연성’을 가진 답을 주는 것은 아닌 그때 그때 좋은 합의에 의한 인공적인 결과물이라는 것이다. 이를 간접적으로 느껴보기 위해 아래의 상황을 가정해 보겠다.
예를 들어 당신이 최근에 이사를 해서 새로운 통근 버스를 정해야 하는 상황이라고 가정해보자. 회사에서 집까지의 동일 노선에는 서로 다른 2종의 버스가 있다. 어떤 버스가 좋을지 판단하기 위해 당신은 1주일 동안 집 앞 정류장에 버스가 도착할 예정 시각에 대해 버스 회사가 제공한 정보와 실제 도착 시각을 조사해본 뒤 다음과 같은 데이터를 얻게 되었다.
자, 그럼 당신은 어떤 버스를 주로 이용하는 것이 가장 좋을까? 당연히 미리 안내된 시각에 잘 맞춰 오는 버스일 것이다. 그런데 ‘잘 맞춰 온다’는 것은 너무 일찍 와도 안 되고 너무 늦게 와도 안 된다는 것을 의미한다. 버스가 예정 시각보다 일찍 오든 늦게 오든 당신이 정류장에서 기다려야 하는 건 매한가지니 말이다. 또 실제 도착하는 시각이 안내 정보와 달리 너무 들쭉날쭉하면 그 버스를 이용해서 출근할 때 마다 매번 마음을 졸여야 한다. 그래서 당신은 각 버스별 예정 시각과 실제 시각의 차를 구한 후 평균을 내보기로 했다.
각 버스별 도착 예정 안내 시각과 실제 도착 시간 데이터(단위: 분)
각 버스회사가 안내한 버스별 도착 예정 시각

실제 조사한 각 버스별 도착 시각

각 버스별 도착 시간의 차이


실제 도착한 시각이 더 늦은 경우는 플러스 값으로, 반대의 경우는 마이너스 값으로 평균을 구했더니…… 이런! 두 버스의 평균이 공교롭게도 동일하게 1이다. 그럼 두 버스 중 어떤 것을 타든 상관없다고 할 수 있을까? 아니다. 중요한 것은 원래의 안내 시각에서 벗어난 정도의 평균값이 아니라 ‘얼마나 많이 벗어나는가’다. 벗어난 정도가 클수록 당신이 정류장에서 기다리는 시간은 길 것이고, 도착 예정 시각에 대한 믿음이 안 생기기 때문이다. 그래서 당신은 또 한 번 가벼운 가공을 해보기로 한다. 바로 각 버스의 도착 예정 시각에서 벗어난 정도, 즉 표준편차를 구하는 것이다. 비록 평균값은 같더라도 ‘평균에서 얼마나 벗어나는가’라는 새로운 기준을 대입하니 1000번 버스가 훨씬 낫다는 것을 금세 알아차릴 수 있다.
1000번 버스의 표준편차가 2000번 버스의 그것보다 작은데, 이는 예정 시각에서 벗어난 정도가 작음을 의미하기 때문이다. 이상은 아주 간단하지만 표준편차라는 개념을 적절히 활용하여 문제를 풀어본, 전형적인 예제 풀이식 데이터 기반 의사결정의 연습이었다. 그럼 이제 이 문제는 시원히 해결된걸까? 어떤 사람은 이런 풀이 과정 어딘가에서 석연치 않은 느낌을 받았을 수도 있다. 이미 정답이라는 게 존재하니 그것에 끼워 맞춰져야 한다고 강요 받은 듯한 느낌 말이다.
각 버스별 요일별 편차의 제공, 분산, 표준 편차

변동의폭 = 3-(-1) = 4

또는 평균치에서 벗어난 정도를 판단의 기준으로 삼아야 한다는 상황 자체가 와닿지 않았을 수도 있다. 그렇다면 문제의 상황을 충분히 자기화하여 다른 방식으로 자기화한 답들이 나올 수 있을지 살펴보자. 문제 인식, 해결 기준 제시, 최선의 해결 방안 지목 등의 모든 과정은 자기 자신을 중심으로 이뤄질 수 밖에 없다. 때문에 개인화된 문제해결 방안이 더 있지 않을지에 대해서도 의식적으로 살펴봐야 한다. 그래야만 유연성과 실천적인 답을 찾아낼 관찰력과 근성이 길러진다.
각 버스회사가 안내한 버스별 도착 예정 시각

실제 조사한 각 버스별 도착 시각

모범 답안에서 한 걸음 더 나아가 자기화한 경우를 생각해보자. 가령 ‘버스가 빨리 오는 상황과 늦게 오는 상황은 절대 같지 않다’고 얘기할 수 있다. 버스가 예정 시각보다 늦게 올 경우 고작 몇 분만 기다리면 되는데 반해 빨리 올 경우엔 아예 버스를 놓치고 말기 때문이다. 주어진 데이터에는 나오지 않았으나 만약 그 다음 버스와의 배차 간격이 길다면 충분히 설득력 있는 주장이다. 즉, 어떤 버스를 탈지 결정하는 기준에 대해 ‘늦게 오는 버스는 조금 기다렸다가 탈 수 있지만 일찍 오는 버스는 정말 문제다’라고 충분히 자기화한 뒤 ‘1000번 버스는 1분 차이로 일찍 왔으나 2000번 버스는 2분 일찍 왔으니 1000번 버스가 더 안정적’이라는 결론을 내릴 수 있다. 물론 ‘1000번 버스가 더 낫다’는 결론 자체는 동일하지만 이유가 바뀔 수 있는 것이다. 그런가하면 ‘내가 왜 버스 도착 시각에 영향을 받아야 해? 난 내 시간에 버스를 맞추겠어’라는 또 다른 자기화도 가능하다. 이런 경우 ‘난 항상 아침 8시에 정류장에 도착한다’는 사람이라면 ‘8시를 기준으로 평균 대기 시간이 짧은 1000번 버스를 택하겠다’는 결론도 충분히 설득력 있는 답이 될 수 있다.
그럼, 각각의 버스가 가장 일찍 오는 시각과 가장 늦게 오는 시각을 파악한 후 그 격차가 작은 버스를 택하는 방법은 어떨까? 1000번 버스는 월요일에 가장 늦게 오고(3분), 수요일에 가장 일찍 오므로(1분) 그 격차는 3-(-1)=4분이 된다. 같은 방식으로 계산하면 2000번 버스의 시간 격차는 7분이 되므로 역시 1000번이 낫다는 결론이다. 표준편차를 활용했던 앞선 방법과 마찬가지로 이 접근법 역시 ‘예정된 시각에서 버스가 벗어나는 경향’을 보겠다는 점은 같다. 하지만 문제가 있다. 실제로는 예정 시각을 더 안 지키는 버스지만 우연히 최대-최소 값의 격차가 적어 더 좋은 버스로 여겨질 수도 있기 때문이다.
이런 식으로 따지면, 얼마든지 다른 방법들을 상상해 볼 수 있다. 예를 들면, 5일 중 정시에 온 횟수가 많은 버스를 ‘성실함’의 기준으로 보는 것이다. 일종의 정시 도착률 같은 것이다. 아니면, 앞서 얘기한 ‘빨리 오는 것과 늦게 오는 것은 같지 않다.’에 착안하여, 5일 중 빨리 오는 경우만을 제외한 날짜수를 세는 방법도 있을 수 있다. 어떤가? 정말 다양하지 않은가?
개념에 대한 가치관에 따라 분석 기법도 달라진다
이렇게 분석의 종류가 다양하게 존재하는 것은 사전적으로 ‘바람직한 버스’에 대한 상(想, 이미지)이 다르기 때문이다. 당연히 이 개념은 매우 주관적일 수 밖에 없고 말이다. 즉, 바람직한이란 개념에 대한 각자의 가치관이 다르기 때문에 그 가치관을 대변하는 분석 기법도 달라지는 것이다. 실제로, 문제를 둘러싼 가치관의 문제는 분석 기법 선정에 매우 중요한 영향을 미친다.
예를 들면, 어떤 사업체의 성과평가를 하려는 경우 그 사업이 어떤 주기(태동-발전-성숙-쇠퇴)에 있느냐에 따라 그 평가지표는 시장점유율(%), 매출액(원), 매출성장률(%), 이익규모(원), 이익성장률(%)등 매우 여러가지로 나타낼 수 있듯이 말이다.
위험도: (기간별 확진자 수 / 기간별 허용 고객 수) * 100 %
이 그림은 코로나 시국에 다중이용시설의 위험도를 그 다중시설에서 발생한 확진자 수로만 볼 것이 아니라, 그 다중시설을 이용한 사람 수 대비 확진자 수로 봐야한다는 취지의 분석 기획 내용이다. 언뜻 들으면 그럴싸 해보인다. 하지만, 잘 생각해보면 확진자 발생 위험도는 효율성 관점이 아닌 효과성 중심으로 볼 문제라고 볼 수 있다. 왜냐하면 10명 중 2명이 발생한 다중위험시설보다 1000명 중 5명이 발생한 다중위험시설이 더 위험하다고 볼 수 있는 이유는 다중이용시설을 이용한 사람들의 편익의 크기와 관계없이 무조건 확진자가 발생한 절대 규모 자체가 적은 것이 방역 관점에서 중요하기 때문이다. 즉, 분석을 지배하는 가치관의 힘에 따라 분석의 내용은 강하게 지배 받을 수 밖에 없는 것이다.
이렇듯, 분석은 각자가 가진 가치관과 그 가치관을 대변하는 분석 어프로치에 따라 늘 다른 답을 주게 되어 있다. 그러니, ‘분석은 정답을 구하는 행위이다.’라는 오해는 ‘나는 맞고, 너는 틀리다.’라는 굉장히 위험한 발상으로 이어질 수 있다. 늘 소통과 합의로 답을 찾는 것이 아니라, 서로 빚어내는 행위라는 것을 알아야 하는 것이다. 내가 앞으로 연속으로 진행될 데이터 리터러시 기고의 첫 글로 이 분석의 유연성을 강조하는 이유는 ‘기법과 툴 중심’의 데이터 학습에 대한 강력한 우려임과 동시에 데이터 기반 문제해결에 대한 좀더 입체적인 이해를 해달라는 당부이기도 하다. 그래야 데이터 리터러시에 필요한 생각하는 힘, 감각, 가치관 같은 단어가 데이터, 분석 기법/툴이란 단어와 함께 등장할 때 어색하지 않을 것이기 때문이다. 다시 말해, 분석은 답을 주는 행위가 아니라 고도의 합의의 산물이라는 생각을 견지해야 매 순간 더 나은 답이 있을 수 있다는 마음의 여유와 근성이 생긴다.