

교육심송용 | 한림대학교 데이터과학스쿨 교수
R에 도전하자···
따라가다보면, 나도 R유저⑤
‘R에 도전하자 ①’부터 ④에서 R의 설치부터 시작하여 몇 가지 기능을 따라 해보고 R에서의 색깔처리, R의 기초적인 통계함수 및 R의 벡터 및 데이터 프레임을 사용한 자료처리에 대해 알아보았다. 이번 호에서는 R의 작업을 저장하고 불러오는 방법과 함수를 작성하여 여러 개의 명령을 한 번에 수행하는 방법에 대해서 알아보기로 한다.

지난 호에서 R에서 데이터 프레임을 만드는 것을 살펴보았다. 이 데이터 프레임에 저장된 자료는 R을 끝낼 때 ‘저장하고 끝내기’를 선택하여 나중에 다시 사용할 수 있음은 알고 있다. 만일 다른 사용자와 이 자료를 공유하려면 어떻게 할지 알아보자.
R의 자료를 다른 R 사용자에게 R 형식을 유지하면서 이메일 등의 방법으로 공유하려면 save 명령으로 R 형식을 유지한 외부 파일로 만들어서 저장하고 저장된 파일을 사용하여 R 객체를 공유할 수 있다. save 함수는 USB 등에 저장하여 다른 컴퓨터에 옮기는 작업을 위해서도 유용한 명령이다. save 함수로 저장된 R 형식의 파일은 load 함수로 불러 올 수 있다.
save와 load 함수는
save(..., file = stop("'file' must be specified"), ...)
및
load(file, ...)
로 사용하며 ...에는 파일로 저장할 R 객체의 이름을 나열하고 file에는 저장하거나 불러올 파일의 이름을 설정한다. 예를 들어 다음 두 개의 R 객체 x.names와 y.freq
> x.names <- c("A", "B", "C", "D")
> y.freq <- c(10, 20, 40, 30)
를 파일명 test1.R로 저장하고자 하면
> save(x.names, y.freq, file="D:/HWP/lecture/기고문/통계진흥원/test1.R")
명령을 사용하여 D:/HWP/lecture/기고문/통계진흥원/ 위치에 test1.R이라는 파일이름으로 x.names와 y.freq를 저장한 R 파일을 만들게 된다. 참고로 윈도우의 경우 경로의 구분에 사용하는 특수문자는 \이지만 R에서 경로구분은 \\ 또는 /를 사용함은 ‘R에 도전하자 ③’에서 설명하였다.
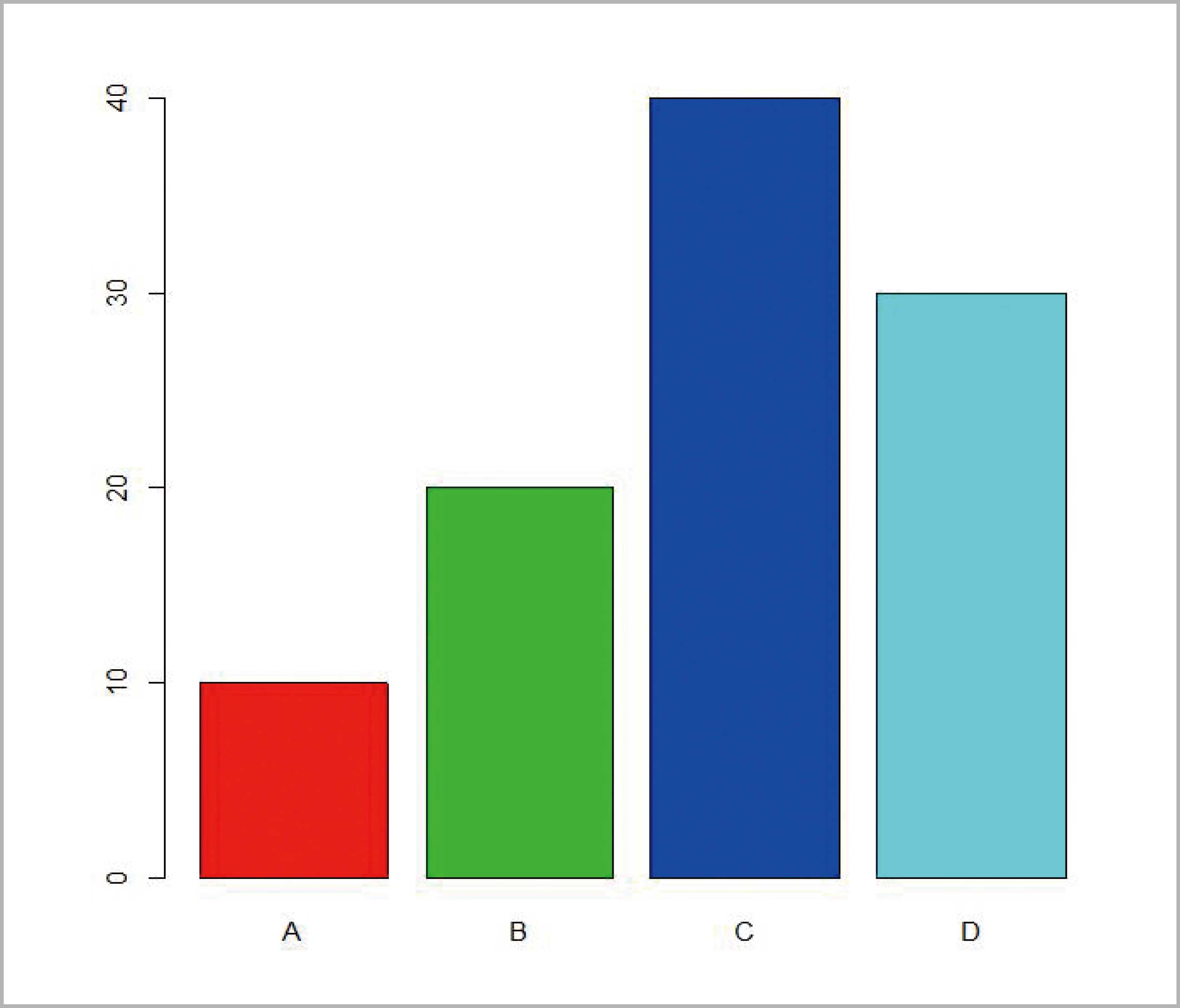
이제 이 두 벡터를 이용하여 막대그래프를 그려보면 > barplot(y.freq, names=x.names, col=2:5)로 그래프가 그려짐을 확인할 수 있다. 하지만 이 경우 조금 전에 만든 x.names와 y.freq라는 두 개체가 삭제되지 않았기 때문에 그려진 것으로 저장한 ‘test1.R’ 함수와는 상관이 없다. 따라서 이 두 객체를 삭제하고 다시 막대그래프를 그려보면
> rm(x.names, y.freq)
> barplot(y.freq, names=x.names, col=2:5)
Error in barplot(y.freq, names = x.names, col = 2:5) :
객체 'y.freq'를 찾을 수 없습니다
로 x.name와 y.freq 라는 객체가 없음을 확인할 수 있다.
이제 앞에서 save 함수를 사용하여 저장한 test1.R 파일의 내용을 불러오려면
> load(file="D:/HWP/lecture/기고문/통계진흥원/test1.R")
명령을 사용하고, 다시 막대그래프를 그리는 명령
> barplot(y.freq, names=x.names, col=2:5)
을 사용하면 앞에서 본 막대그래프가 정상적으로 그려짐을 알 수 있다.
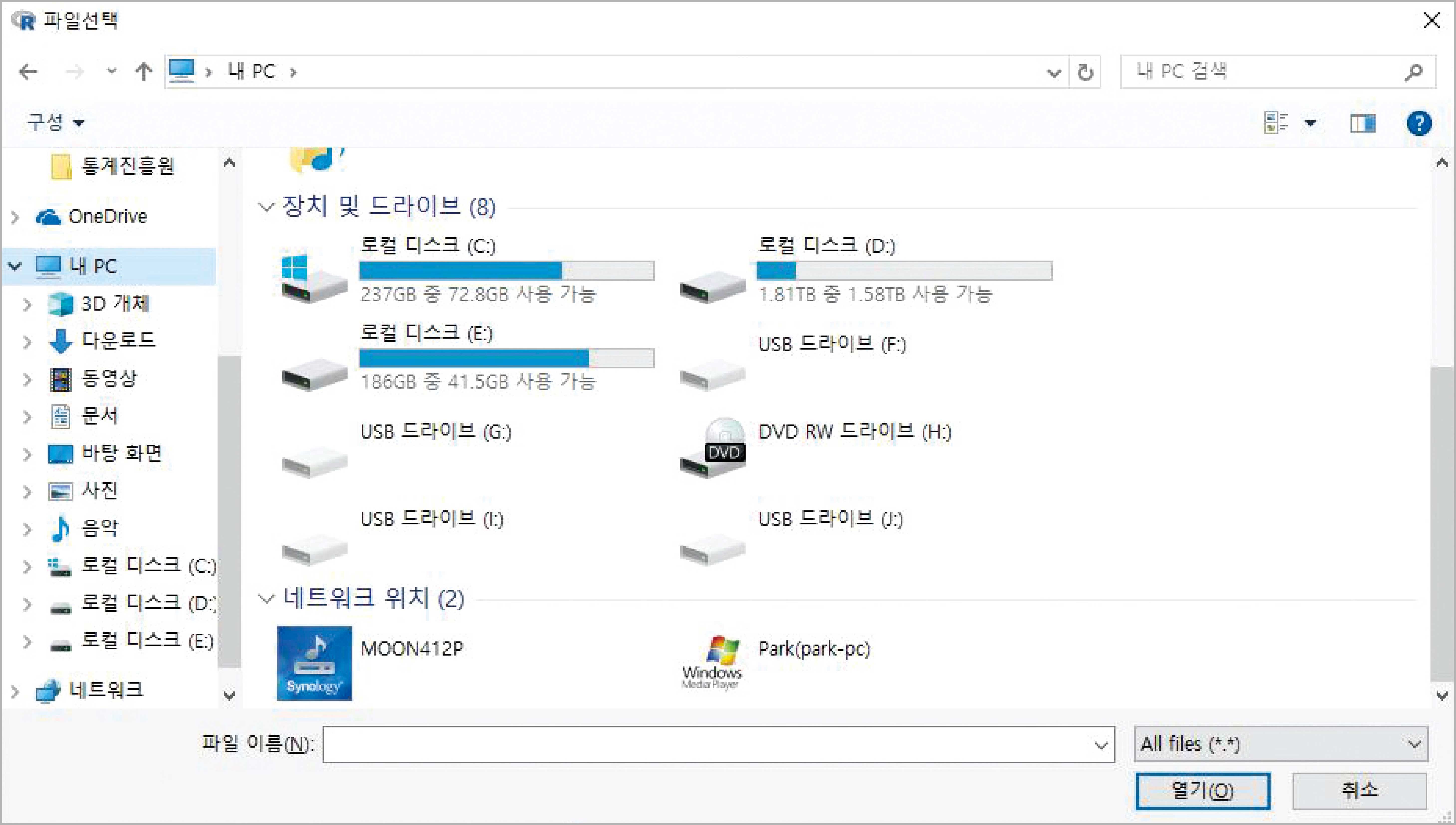
파일을 저장하거나 읽어 들이기 위해 앞에서 사용한 save나 load 함수는 파일의 전체경로를 포함한 긴 파일이름을 입력하는 불편함이 있을 수 있으며1), 또 한 가지 위험한 것은 save 함수는 기존에 같은 이름의 파일이 있더라도 말없이 덮어 쓴다는 것이다. 이 두 가지 문제를 해결하는 방법 중의 하나가 save나 load 함수의 매개변수 file에 file.choose 함수를 사용하는 것이다. 이 함수를 사용하면 윈도우에서 파일 열기나 저장하기에서 보는 파일 탐색기가 열려서 내가 원하는 위치에서 원하는 파일 이름으로 저장하게 해준다. 즉,

> save(x.names, y.freq, file=file.choose())
및
> load(file=file.choose())
를 사용하면 그림 과 같은 파일 탐색화면이 만들어지므로 이 화면에서 저장할 파일의 이름 또는 불러 올 파일의 이름을 정할 수 있다.


어떤 작업을 완성하기 위해 자료를 읽고, 분석하는 함수를 사용하는 등 여러 개의 명령을 수행할 경우가 있다. 이럴 때 매번 R 명령을 입력하지 않고 명령을 저장해 두었다가 명령을 실행시킬 수 있다. 이 때 사용할 수 있는 R 함수로 source 함수가 있다. source 함수는
source(file, echo = verbose, encoding = getOption("encoding"), ...)
로 사용하며 file에는 R 명령어가 저장되어 있는 텍스트 파일의 이름을 설정하고, echo에는 file에 있는 명령을 R에 다시 보여줄 것인지 설정한다. encoding에는 file에 사용한 encoding을 설정한다.
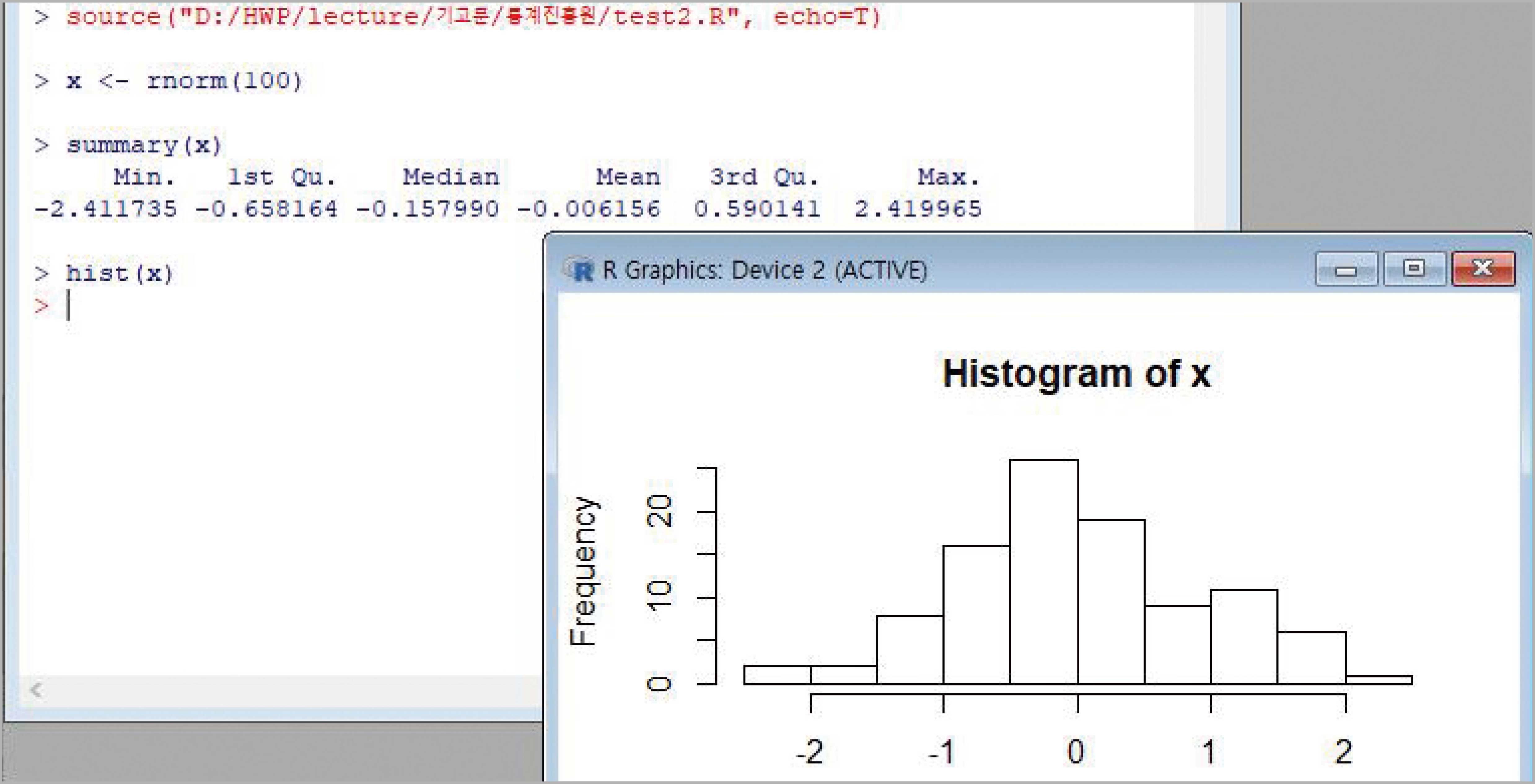
예를 들어 다음과 같이 정규분포에서 난수를 생성하고, 이 난수를 사용하여 히스토그램을 만드는 과정을 생각해보자. 이 작업을 위해서
x <- rnorm(100)
summary(x)
hist(x)
순서로 세 명령어를 사용하려고 한다. 이 세 가지 명령을 적당한 폴더에 test2.R이라는 파일 이름으로 저장하고 이 파일을 source 함수로 불러오면 이 세 명령이 실행된다. 여기서 사용한 rnorm 함수는 R에 내장된 통계함수로 정규분포에서 난수를 생성하는 함수이다. 이 경우 100개의 난수를 생성하여 x에 저장한다. 위의 세 명령이
“D:/HWP/lecture/기고문/통계진흥원/test2.R”
에 저장되어 있다면(이 명령은 텍스트 파일로 구성되므로 이 파일을 만들기 위해서 윈도우의 경우 메모장 또는 그 외 텍스트 편집기를 사용하는 것이 좋다)
> source(file="D:/HWP/lecture/기고문/통계진흥원/test2.R", encoding="UTF-8")
로 이 파일에 저장된 R의 명령을 실행할 수 있다. 위의 명령의 결과는 100개의 정규분포 난수를 저장한 x의 히스토그램만 만들어지고 이 파일 안에 있는 summary(x) 명령의 결과는 출력되지 않음을 알 수 있다. 기본적으로 source 함수는 R 콘솔창의 출력은 만들지 않도록 설정되어 있기 때문이다. 만일 명령을 실행하고 그 결과를 콘솔창에서 보려면 옵션으로 echo에 TRUE를 설정하여야 한다. 즉,
> source("D:/HWP/lecture/기고문/통계진흥원/test2.R", echo=T)
의 결과는 다음과 같다. 이 명령에서는 ‘file=’이 생략되었다.
source 함수에서도 읽어 올 파일이름을 지정하지 않고 file에는 file.choose 함수를 사용할 수 있다. 즉,
> source(file=file.choose(), echo=T)
를 사용하면 파일 탐색기가 열리고 파일 탐색기에서 읽어 들일 파일을 지정할 수 있다.

많은 업무는 비슷한 작업을 반복하는 경우가 많다. R을 사용하여 분석 작업을 하는 경우도 역시 마찬가지일 것이다. R 사용자가 많이 사용할 것으로 생각되는 여러 가지 기능은 기본 R의 설치시 자동으로 설치된다. 예를 들면 mean 함수는 평균을 계산해주는 함수, quantile은 분위수를 계산해주는 함수이며, 앞에서 본 barplot이나 hist 함수는 막대그래프나 히스토그램을 그리는 함수이다.
하지만 R이 제공하는 함수가 모든 사용자의 필요성에 100% 대응할 수는 없으므로 때로는 사용자가 자주 사용하는 기능을 포함하는 함수를 작성할 필요성이 제기된다. 함수의 작성은 function이라는 키워드를 사용하여 다음과 같이 작성한다.
fcn_name <- function(par1=val1, par2=val3, ...) {
이 함수의 수행에서 사용할 명령들을 입력
list 또는 return 함수로 함수의 결과를 반환
}
위의 함수 정의에서

◆ fcn_name에는 함수의 이름을 지정하며 함수의 이름은 변수의 이름과 마찬가지로 특수문자를 제외한 문자로 지정할 수 있다.
◆ par1, par2 등은 이 함수가 실행될 때 전달되는 매개변수의 값이며 매개변수가 없는 경우 이 부분을 생략할 수 있다.
◆ val1, val2 등은 함수를 호출할 때 매개변수 par1, par2의 값이 설정되지 않을 경우 사용할 기본값을 설정한다.
◆ list 함수 또는 return 함수를 사용하여 함수의 결과를 따로 반환할 수 있으며 결과를 출력하고 싶지 않다면 생략될 수 있다.
이와 같이 함수가 정의되었다면 위의 함수는 R에서 fcn_name(val1, val2)
와 같이 호출하거나 함수의 결과를 저장하려면
result1 <- fcn_name(val1, val2)
와 같이 함수의 결과를 result1에 저장한다.
함수 작성의 몇 가지 보기를 이용하여 함수 사용의 방법을 알아보자.
보기 1. 벡터 x를 입력받아서 x의 길이(표본크기), 표본평균(),
표본분산밑 모분산을 출력하는 함수를 작성 해보자. 함수 호출시 x를 지정하지 않으면 x의 값으로 표준정규분포의 난수 100개를 사용하기로 한다.
풀이: 이 함수의 이름을 bstat1이라고 하여 다음과 같이 함수를 작성하자.
bstat1 <- function(x=rnorm(100)) {
n <- length(x)
xbar <- mean(x)
s.var <- var(x)
p.var <-s.var * (n-1) / n
list(n = n, mean=xbar, sampleV = s.var, popV = p.var)
}
이 함수는 함수가 호출될 때 매개변수 x가 함수로 전달되어 전달받은 x를 사용하여 원하는 값 네 개를 계산하고(n, xbar, s.var, p.var) 이 값을 list 함수를 사용하여 각각의 이름을 n, mean, sampleV, popV로 반환하는 함수이다.

위의 함수를 R에 입력하고 아래와 같이 이 함수 bstat1을 호출하면
> bstat1(seq(1,100))
결과는
$n
[1] 100
$mean
[1] 50.5
$sampleV
[1] 841.6667
$popV
[1] 833.25
로 1부터 100까지의 자연수에 대해서 한 번에 필요한 출력을 모두 얻는다. 만일 함수의 결과를 특정한 변수로 저장하려면
> x <- c(1,2,3, 6,7,8, 9,10,11)
> res1 <- bstat1(x)
로(이 경우 사용할 자료는 함수 호출 전에 정의된 x로 9개의 자료이다) 함수의 결과는 res1에 모두 저장되어 있다. res1에 저장된 개별 값은 $부호를 사용하여

> res1$mean
[1] 6.333333
> res1$popV
[1] 11.55556
와 같이 호출하거나
> res1[[2]]
[1] 6.333333
와 같이 몇 번째 값인지를 설정하여(이 경우 두 번째 값) 원하는 결과만 따로 뽑을 수 있다
함수를 작성한다는 것은 여러 개의 명령을 한 번에 실행하는 것이므로 여러 R 명령을 하나씩 입력하여야 한다. 하지만 여러 개의 명령어를 한 번에 입력할 경우 오타 등으로 중간에 에러가 발생하는 것을 거의 피할 수 없게 되어 함수를 사용하는 의미가 퇴색될 수밖에 없다. 따라서 함수를 사용한다는 거의 필연적으로 함수의 내용을 파일로 저장한 후 앞에서 본 source 함수 등을 사용하여 이 함수를 읽어 들이게 된다. 이것이 source 함수를 사용할 때 출력을 만들지 않는 것이 source 함수의 기본값인 이유 중의 하나이다. 이제 위의 함수 bstat1을 적당한 위치에 파일로 저장하자. 이 파일을
“D:/HWP/lecture/기고문/통계진흥원/bstat1.R“
에 저장하고 R에서
> source("D:/HWP/lecture/기고문/통계진흥원/bstat1.R")
라고 하면 이 함수가 읽히게 된다. 이 때 아무런 출력이 만들어지지 않지만 함수의 내용을 모두 읽어 실행되었으므로 bstat1(x)를 명령하면 필요한 결과를 얻게 된다.
보기 2: 위의 함수 bstat1을 매개변수 없이 호출하여 보자. 즉
> bstat1()
을 명령하면2) 다음의 결과를 얻게 되며
$n
[1] 100
$mean
[1] -0.01102791
$sampleV
[1] 1.155612
$popV
[1] 1.144056
이 결과는 함수의 정의에서 사용한 x=rnorm(100)에 의해서 x의 값이 지정되지 않은 경우에 해당되어 x의 값으로 기본값인 rnorm(100)을 사용하여 얻은 결과이다. 그런 이유로 평균은 0, 분산은 1에 가까운 결과를 얻었다3).
참고: 매개변수가 없더라도 함수를 호출할 때는 반드시 괄호를 사용하여 함수를 호출하여야 하며 괄호 없이 함수이름만 입력하면 함수의 내용을 확인하게 된다. 즉,

> bstat1
function(x=rnorm(100)) {
n <- length(x)
xbar <- mean(x)
s.var <- var(x)
p.var <- s.var * (n-1) / n
list(n = n, mean=xbar, sampleV = s.var, popV = p.var)
}
을 얻게 된다.


R의 매뉴얼을 보면 함수의 설명에서 ...(빈 칸 없이 마침표 세 개 연속)을 자주 보게 되는데 이 ...은 함수 정의에서 특별한 의미를 갖는다. 이 ...은 함수의 매개변수로 직접 사용하진 않더라도 함수 내에서 호출되는 다른 함수의 매개변수로 사용된다. 예를 들어
mymean1 <- function(x, ...) {
xbar <- mean(x, ...)
list(mean = xbar)
}
로 mymean1을 정의하고 x를
> x <- c(1, 2, 3, 4, 5, NA)
로 정의한 후 이 함수를 아래와 같이 호출하며
> mymean1(x)
$mean
[1] NA
결측값 NA에 의해서 평균은 NA가 된다. 반면 다음과 같이
> mymean1(x, na.rm=T)
이 함수를 호출하면(여기서 함수 mymean의 정의에는 na.rm이란 매개변수가 정의되지 않았고 ... 만 있음에 유의하자) 결과는
$mean
[1] 3
가 얻어진다. ... 위치에 적용된 na.rm=T가 mean 함수의 호출에서 사용된 ...에 대입되면서 결측치를 제외한 값들의 평균이 얻어진 것이다. 참고로 mean 함수는 결측치를 제외할 수 있는 옵션으로 na.rm의 값을 설정할 수 있으며 이 값의 기본값이 FALSE라서 결측치가 있으면 평균값도 NA가 된다.