


통계광장심송용 | 한림대학교 금융정보통계학과 교수
R에 도전하자···
따라가다보면, 나도 R유저③
R에 도전하자 ①, ②에서 R의 설치부터 시작해 몇 가지 기능을 따라 해보고 R을 끝내는 과정과 R에서 할 수 있는 색깔 처리에 대해 알아보았다. 이번 호에선 데이터분석을 위해 R에 자료를 저장하고 이를 이용하는 방법을 알아보기로 한다. R이 아니더라도 분석을 위해서 데이터를 만지는 과정(data manipulation)은 전체 분석 과정에서 시간이 많이 걸리고 데이터마다 처리해야 할 절차가 달라 복잡하다.
한 변수에 대한 자료 저장
예를 들어 어느 학급의 국어 성적이 다음과 같을 때

이를 분석하기 위해 국어 성적을 한 변수에 저장하려면
> score <- c(80, 90, 75, 50, 95, 80, 84, 92, 88, 79)
로 c 함수(combine이란 뜻)를 사용해 score라는 변수에 여러 개의 값을 저장할 수 있음을 R에 도전하자 ①에서 다루었다. 이와 같이 한 변수에 1차원적인 여러 개의 값을 저장한 것을 R에서는 벡터(vector)라고 부른다. 벡터는 엑셀의 스프레드시트에서 하나의 행 또는 열에 모든 자료가 저장된 경우로 생각하면 된다.
벡터에서 특정한 위치의 값을 불러오고자 할 때는 [ ]사이에 해당 번호를 설정한다. 예를 들어 score의 세 번 째 값은 [3]을 사용해
> score[3]
[1] 75
로 얻으며 여러 개의 값을 추출하려면 해당 번호를 벡터로 설정한다. 예를 들어 3, 4, 5번째 값을 얻으려면
> score[3:5]
[1] 75 50 95
또는 score[c(3,4,5)]로 얻을 수 있다. -(빼기 부호)를 사용하면 주어진 번호를 제외한 나머지 값을 얻을 수 있다. 첫 번째 두 번째 및 네 번째 자료를 제외한 나머지 값들은
> score[-c(1,2,4)]
[1] 75 95 80 84 92 88 79
와 같이 얻는다.
특정 조건에 해당하는 자룟값을 얻고자 할 때도 해당 조건을 [ ] 안에 설정한다. 예를 들어 점수가 90 이상인 학생의 번호는
> score[score > = 90]
[1] 90 95 92
로 얻는다. >=와 같이 두 개의 값을 비교하는 연산자를 비교연산자라고 하는데 R에서 비교연산자는 다음 표와 같다.
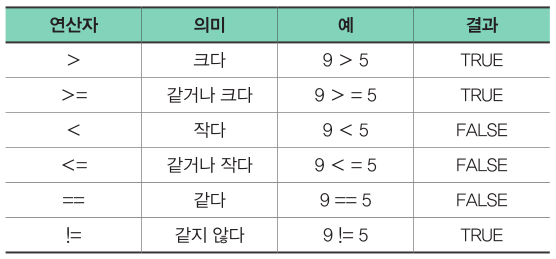
which 함수는 주어진 조건에 맞는 번호를 찾아준다. 예를 들어 점수가 90 미만인 학생이 몇 번째 학생인지 알아보려면
> which(score < 90)
[1] 1 3 4 6 7 9 10
으로 첫 번째, 세 번째, 10번째 점수가 90 미만임을 알 수 있다.
1.1 백터의 연산
백터의 연산은 원소 대 원소로 이루어진다. 즉 길이가 n인 두 벡터 x와 y의 합 x+y의 계산은 x[1]+[y[1],x[2]+y[2], x[n]+y[n] 으로 x+y가 계산된다. 이 연산은 합뿐 아니라 -(빼기), *(곱하기),/(나누기) 등의 산술연산 및 위의 논리연산 등 모든 연산에 적용된다.
> x <- 1:5 # x는 1부터 5까지 길이 5인 벡터
> y <- 5:1 +1 # y는 6, 5, 4, 3, 2
> x+y #1+6, 2+5, 3+4 등을 계산
[1] 7 7 7 7 7
> x*y # 1x6, 2x5, 3x4 등을 계산
[1] 6 10 12 12 10
> x > y # 1>6, 2>5, 3>4, 4>3,5>2 등을 비교해 참/거짓을 얻음
[1] FALSE FALSE FALSE TRUE TRUE
앞의 경우 길이가 같은 두 벡터의 연산을 살펴보았다. 만일 두 벡터의 길이가 같지 않으면 어떻게 계산할까? R은 길이가 같지 않은 두 벡터의 연산은 길이가 같지 않은 두 벡터의 연산은 길이가 작은 쪽을 반복해 사용한다. 예를 들어 x는 1, 2, 3, 4 이고 y는 1, 2이면 y의 길이가 x의 길이보다 작으므로 y값을 반복해 x[1]+y[1], x[2]+y[2], x[3]+y[1], x[4]+y[2]를 계산한다.
> x <- 1:4; y <- 1:2
> x+y # 1+1, 2+2 후에 y가 모자라므로 y의 첫 번째 값부터 다시 3+1 4+2를 계산
[1] 2 4 4 6
길이가 같지 않은 벡터의 연산에서 짧은 쪽 길이가 긴 쪽 길이의 배수가 되지 않으면(위의 경우 짧은 쪽 길이는 2, 긴 쪽 길이는 4로 짧은 쪽 길이가 긴 쪽 길이의 2배로 배수임), 계산은 위와 같이 하지만 경고 메시지를 출력한다.
> x <- 1:4; y <- 1:3
> x+y # 1+1, 2+2, 3+3 후에 y가 모자라므로 y의 첫 번째 값부터 다시 4+1
[1] 2 4 6 5
경고메시지(들):
In x+y : 두 객체의 길이가 서로 배수관계에 있지 않습니다
두 벡터의 길이가 같지 않을 때 일반적으로 계산에 조심해야 하지만 이 성질을 이용하면 모든 벡터에 같은 값으로 연산을 할 때 편리하다. 예를 들어 벡터의 모든 값에 2로 나눈 나머지를 얻고자 한다면(0 또는 1)
> x <- 1:5
> x %% 2 # x를 2로 나눈 나머지의 계산. 참고로 몫은 %% 연산자로 얻음.
[1] 1 0 1 0 1
를 얻을 수 있다. 이를 이용하면 x 중의 홀수의 개수는
> sum(x %% 2)
[1] 3
으로 얻을 수 있다.

여러 개의 변수와 데이터 프레임(data frame)
여러 개의 변수를 가진 자료를 R에서 분석하려면 데이터 프레임을 사용하는 것이 좋다. 많은 R의 내장함수가 자료가 데이터 프레임으로 저장되어 있는 경우를 선호한다. R에서 데이터 프레임을 만드는 방법은 몇 가지 방법이 있다.
2.1 벡터로 구성된 개별 자료를 하나의 데이터 프레임으로 구성하는 경우
키, 몸무게, 성별이 각각의 벡터로 x, y, z에 저장된 경우 이를 하나로 묶어 데이터 프레임을 만들 수 있다. 이때 사용하는 함수는 data.frame 함수이며
data.frame(name1=var1, name2=var2, ...)
로 사용한다. 여기서 namei=vari의 짝은 R의 벡터 vari를 만들어지는 데이터 프레임에서 변수 이름 namei로 저장한다는 의미이다. 만일 namei=를 생략하고 벡터 이름만 나열하면 벡터 이름이 데이터 프레임에서의 변수 이름이 된다. 예를 들어 키, 몸무게 및 성별이 각각의 벡터 x, y, z에 저장되어 있는데 이를 하나의 데이터 프레임으로 저장하는 경우를 생각해보자.

추후 사용자 편의를 생각해서 키는 height, 몸무게는 weight, 성별은 gender라는 변수 이름을 설정해 보면
> mydf <- data.frame(height=x, weight=y, gender=z)
> mydf
height weight gender
1 170 65 M
2 175 67 M
3 180 74 M
4 162 54 F
5 158 50 F
로 데이터 프레임을 만들 때 변수 이름이 설정됨을 알 수 있다.
데이터 프레임에서 특정한 위치의 자료를 얻는 방법은 벡터에서와 마찬가지로 [ ]사이에 조건을 설정한다. 데이터 프레임인 경우 행렬 형태로 되어 있으므로 벡터와 달리 얻고자 하는 자료의 행과 열번호가 필요하다. 따라서 [ ] 안에 행번호와 열번호를 설정하고 이 두 값 사이에 콤마(,)를 사용한다. 만일 두 번째 자료의 성별을 알고 싶으면 두 번째 행, 세 번째 열이므로
> mydf[2,3]
[1] M
Levels: F M
이 얻어진다. 이 경우 ‘Levels: F M’은 이 자룟값(성별)이 두 개의 값 F, M으로 구성되어 있는 요인(factor)이라는 의미이다. factor에 대해서는 추후 자세히 다루기도 한다.
특정한 조건의 행, 또는 열을 모두 얻고 싶으면 해당 조건을 행 또는 열의 위치에 설정하고 조건에 해당하지 않는 열 또는 행은 비워두면 된다. 예를 들어 첫 번째 열(키)만 얻고자 하면 키는 첫 번째 열이므로 열번호는 1, 행번호는 비워 두면 된다. 즉,
> mydf[,1]
[1] 170 175 180 162 158
를 얻는다. 이를 확장하면 논리연산자를 사용해 특정 조건에 대한 검색도 가능하다. 예를 들어 남자 자료만 얻고자 한다면 행의 조건에 mydf[,3]이 M인 경우이므로
> mydf[mydf[,3] == “M”,]
height weight gender
1 170 65 M
2 175 67 M
3 180 74 M
으로 얻을 수 있다.
데이터 프레임에서 특정한 변수만 얻으려면 위의 열번호 설정으로 할 수도 있으나 좀 더 편하게 변수 이름을 사용할 수 있다. 이때는 데이터 프레임 이름에 달러 표시($)와 해당 변수 이름을 넣으면 된다. 키를 얻고자 할 때는
> mydf$height
[1] 170 175 180 162 158
로 얻을 수 있으며 성별만 따로 추출하려면 같은 방법을 사용해
> mydf$gender
[1] M M M F F
Levels: F M
을 얻는다.
데이터 프레임이 구성된 경우 summary 함수를 사용하여 기초통계를 얻을 수 있다. 이 함수를 사용하면 수치형 자료인 경우 평균 등의 통계수치를, 성별과 같이 범주형 자료인 경우 빈도에 대한 요약을 얻는다. 한편 plot 함수는 모든 가능한 산점도를 그려준다.
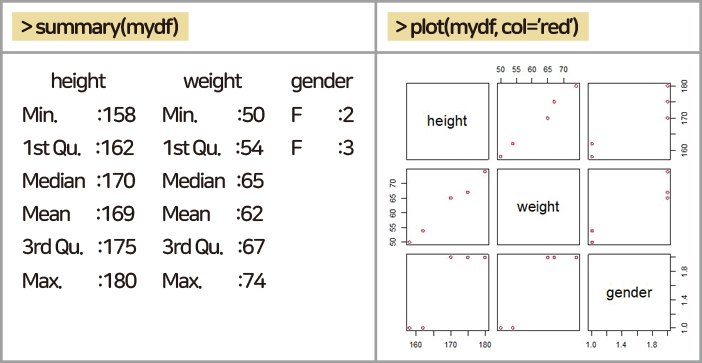
이 출력에서
· summary 함수 height, weight는 수치형 자료이므로 평균, 중앙값, 최대, 최소 및 사분위수가 출력되었고 성별은 범주형이므로 여자 2, 남자 3명인 빈도 수를 확인할 수 있다.
· plot 함수 height와 weight는 수치형으로 키와 몸무게, 몸무게와 키의 산점도가 얻어지며 범주형인 gender에 대해서는 F일 때와 M일 때 키와 몸무게의 점도표를 얻게 된다.
2.2 텍스트 파일에 저장된 자료 읽기
이미 텍스트문서 편집기(윈도우의 경우 메모장 등, 한글이나 워드의 경우 ‘파일’ → ‘다른 이름으로 저장’ → (문서형식을) 텍스트 문서 또는 CSV 문서로 저장한 경우 등을 포함) 등을 사용하여 자료가 텍스트파일로 컴퓨터에 저장되어 있고 이 자료를 R에서 바로 읽어 들이는 경우에 사용할 수 있다. 이때 사용할 수 있는 함수는 read, table 함수이다. 이 함수는
read.table(file, header = FALSE, sep = “”, ...)
로 사용하며
· file 데이터가 저장된 텍스트파일의 이름을 설정한다. 파일의 경로를 \\ 또는 \로 한다. 예를 들어 데이터가 저장된 파일이 D:\mydata\test.txt 이면 file의 설정값은 ‘D:\\mydata\\test.txt’ 또는 ‘D:/mydata/test.txt’ 이다. 파일이름은 작은따옴표나 큰따옴표 안에 적어 주어야 함에 유의한다.
· header 파일의 첫 줄이 변수 이름인지 여부를 설정한다. 첫 줄이 변수 이름이 아니면 기본값이 F이므로 생략 가능하다.
· sep 값들 사이의 구분자(separator)로 사용하는 문자를 설정한다. 기본값은 “”로 빈칸이므로 빈칸으로 값들이 구분되어 있으면 생략 가능하다. 만일 CSV 파일이라고 하는데 CSV 파일의 입출력은 read.csv와 write.csv 함수를 사용할 수도 있다.
앞에서 사용한 자료가 D:\kspi\test.txt 라는 파일에 아래의 왼쪽과 같이 첫 줄에는 변수 이름이 들어가 있는 형태로 저장되어 있을 때 오른쪽의 R 명령으로 이 파일을 R의 데이터 프레임으로 읽을 수 있다.
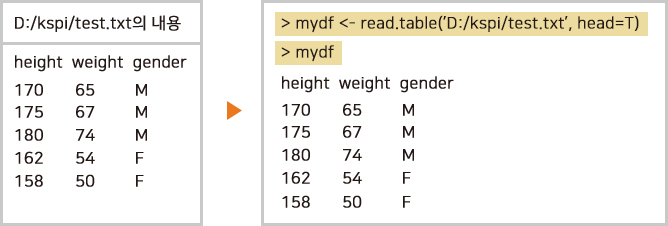
2.3 엑셀 파일 읽어오기
자료를 입력해야 할 때 실무자들이 엑셀 형식으로 저장하는 것을 편하게 느끼는 경우가 많다. 엑셀 파일을 R에서 직접 읽어오는 방법은 xlsx 패키지 등을 사용해 read.xlsx, write.xlsx 등의 함수로 엑셀 파일 읽기 및 엑셀파일로 저장하기가 가능하나 지면의 제약으로 이 부분은 나중으로 미루고 약간의 편법으로 엑셀 파일을 읽는 방법을 알아보자. 이 방법은 엑셀 파일을 콤마로 분리한 텍스트 파일(CSV) 파일로 저장해 이를 텍스트 파일로 읽어오는 방법이다.
1. 읽을 엑셀 파일을 연다. 이 파일을 ‘test.xlsx’라고 하자.
2. ‘파일’ → ‘다른 이름으로 저장하기’ 순서로 메뉴를 선택한다.
3. 이 때 만들어진 창에서 ‘파일형식(T)’를 선택하여 ‘CSV(쉼표로 분리) (*.csv)’를 선택한다.
4. 저장 버튼을 클릭한다.
5. 이제 저장된 파일이 ‘test.csv’이므로 이 파일을
> read.table(’test.csv’, sep=”,”)
명령으로 읽어 들인다. 콤마로 분리된 파일은 read.csv 함수를 사용하여 읽을 수도 있다.
참고 read.table 함수에 대응해 데이터 프레임을 자료를 텍스트 파일이나 CSV 파일로 저장하는 함수도 R에서 제공하며 이 함수는 write.table, write.csv 함수들이다.
2.4 fix와 View 함수
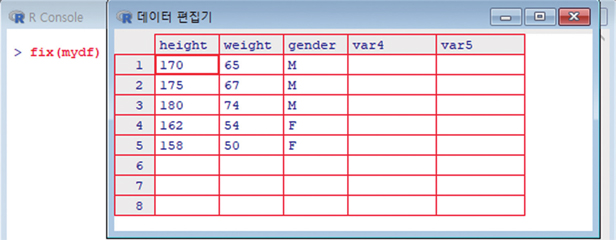
R에서 데이터 프레임(사실 모든 자료가)은 엑셀 등의 프로그램처럼 시각적으로 보이지 않아서 R을 처음 사용하는 사람에게 어려움을 준다. 엑셀 등의 스프레드시트 형태로 데이터 프레임의 자료를 보여주는 함수를 R에서 제공하는데 이 함수는 fix와 View이다. fix 함수는 데이터 프레임에 대한 간단한 입력/수정이 가능한 함수이고 View 함수는 데이터 프레임을 보여주기만(읽기 전용) 한다. 그림은 앞에서 사용한 데이터 프레임 mydf를
> fix(mydf)
로 띄운 화면이다. fix 함수에서 각 자료를 수정/추가/삭제 등이 가능하나 아주 기본적인 기능만 가지고 있다. 값의 입력/변경 등은 해당 셀을 더블 클릭하고 값을 입력/변경한다. 변수 이름의 변경도 같은 방법으로 변수 이름을 입력한다. 수정한 데이터 프레임의 자룟값을 저장하는 것은 fix 함수로 생긴 창의 X표시를 클릭하여 닫는 것이다.
View 함수는 fix 함수와 같은 형태의 출력을 만들어주나 자료를 보기 위한 함수이므로 더블 클릭으로 자룟값을 바꿀 수는 없다.
