ISSUE심송용 | 한림대학교 데이터과학스쿨 교수
R에 도전하자…
따라가다보면, 나도 R유저④
‘R에 도전하자 ①’부터 ③에서 R의 설치부터 시작하여 몇 가지 기능을 따라 해보고 R을 끝내는 과정과 R에서의 색깔처리 및 R의 벡터 및 데이터 프레임을 사용한 자료처리에 대해 알아보았다. 이번 호에선 기본적인 데이터 분석을 위한 R의 함수에 대해 알아보기로 하자. 대개 자료를 분석하기 위한 첫 걸음으로 자료에 대한 수치요약 및 표나 그림을 사용한 요약이 사용된다.
통계수치 계산함수
R에서 기초적인 통계수치를 계산할 수 있는 함수는 다음과 같다.
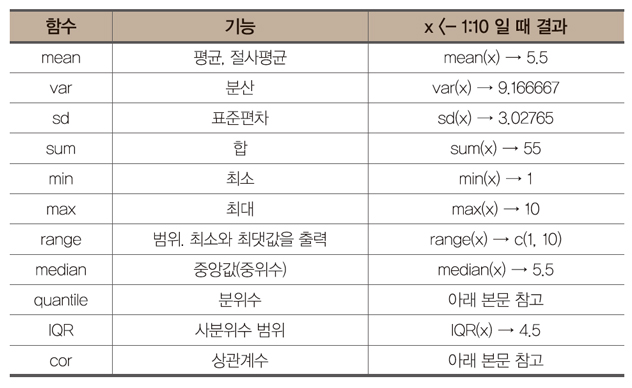
· mean 함수의 경우 산술평균을 계산해주며, 옵션에 trim의 값을 설정하면 절사평균(trimmed mean: 큰 값의 일부와 작은 값의 일부를 제외한 평균)을 얻을 수 있다.
> x <- c(1:9,11)
> mean(x, trim=0.1) # 전체 자료중 가장 큰 10%와 가장 작은 10%를 제외한 나머지 자료의 평균인 5.5를 얻는다.
· var와 sd: 각각 분산과 표준편차를 계산해주며 실제 사용하는 식은 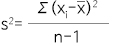 으로 분모에 n이 아닌 (n-1)을 사용한다.
으로 분모에 n이 아닌 (n-1)을 사용한다.
· range: range 함수는 최솟값과 최댓값을 한 번에 계산하여 그 결과가 백터이다. 따라서 최솟값은 range 함수의 결과 중 첫 번째 값, 최댓값은 range 함수의 결과 중 두 번째 값이며 범위를 직접 계산 해주는
것은 아님에 유의하여야 한다.
> x <- 1:10
> range(x)
[1] 1 10
> range(x)[1] # 최소값
[1] 1
> range(x)[2] # 최대값
[1] 10
· quantile: (백)분위수를 계산해주며, 다른 값을 설정하지 않으면 최소, 25%백분위수, 50%백분위수, 75%백분위수 및 최댓값을 계산한다.
> quantile(x, prob=c(0.05,0.95))
0% 25% 50% 75% 100%
1.00 3.25 5.50 7.75 10.00
이들 기본값이 아닌 백분위를 값을 구하고자 할 때는 prob에 해당 값을 0과 1사이의 값으로 설정한다.
예를 들어 5% 백분위와 95% 백분위수를 얻으려면 0.05와 095를 설정한다.
> quantile(x)
5% 95%
1.45 9.55
로 5% 백분위수는 1.45, 95% 백분위수는 9.55를 얻는다.
수학함수
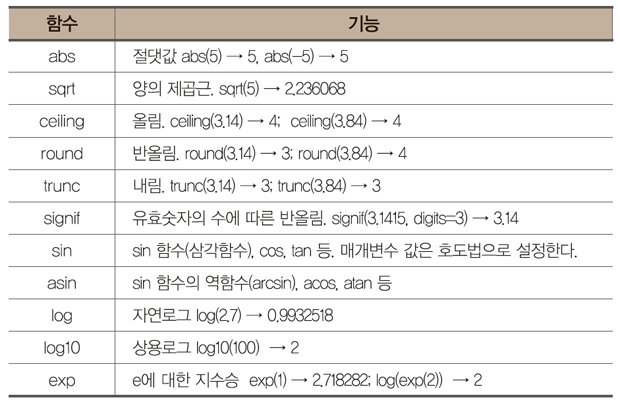
· round와 signif 함수는 digits에 소수점이하 자리수 및 전체 유효숫자의 개수를 설정할 수 있다.
> round(3.141592, digits=3)
[1] 3.142
· 삼각함수는 호도법을 사용한다. pi는 R의 내장된 상수로 π=3.141592… 값을 저장하고 있다.
> sin(pi/2) # sin(90˚) = sin(π/2) = 1
[1] 1
> atan(1) # tan-1(1)=45˚ = π/4 = 0.7585
[1] 0.7853982
> pi/4
[1] 0.7853982
문자열 함수
R의 결과를 요약하는 경우나 그림을 그리는 경우 문자열을 다루게 되는 경우도 많다. 이런 경우 문자열을 처리하는 함수를 사용할 수 있다.
grep이나 sub 함수에서
· ignore. case는 영문의 대소문자를 구별할지 설정한다. 기본값은 FALSE로 구분하지 않는다.
· fixed는 pattern이 일반적인 문자열인지 설정하는 것으로 pattern이 일반 문자열이 아니고 정규식(regular expression)인 경우에 FALSE이며 FALSE가 기본값이므로 일반 문자열인 경우 TRUE로 설정을 변경해야
한다.
빈도(도수분포표) 및 교차표
자료의 값이 범주형인 경우(예를 들어 성별, 거주지역 등) 자료를 요약하기 위해 각 범주의 값에 대한 빈도를 표로 제시하는 경우가 많다. 한 벡터에 대해서는 도수분포표가 두 개의 변수에 대해서는 교차료가
많이 사용되며 이 두 가지 모두 R의 내장함수 table을 사용하여 얻을 수 있다. table 함수는
table(...,) dnn = list.names(...))
로 사용하며
· ...에는 행과 열에 사용할 벡터의 이름을 설정한다. 벡터 이름 한 개만 줄 경우 도수분포표가 얻어진다.
· dnn에는 행과 열의 이름을 설정한다.
R에는 데이터 프레임도 많이 내장되어 있다. 그 중 하나가 mtcars라는 데이터 프레임이다. 이 데이터 프레임에는 1974년 Motor Trend US라는 자동차관련 잡지에 소개된 32개의 1973년 및 1974년식 자동차의
10개의 특성을 저장한 데이이터 프레임이다. 이 특성은 mpg(1갤론당 주행거리), cyl(실린더의 개수), disp(배기량), gear(전진기어의 단수) 등이다. 이 데이터 프레임에 대한 자세한 설명은 R에서 help(mtcars)
명령으로 볼 수 있다.
이 데이터 프레임을 사용하여 실린더 개수(cyl)의 도수분포표를 얻으려면
> table(mtcars$cyl)
4 6 8
11 7 14
로 4기통, 6기통 8기통이 각각 11대, 7대 및 14대 있음을 알 수 있다. dnn을 사용하여 사용한 벡터의 이름을 “N of cylinders”로 설정해보면
> table(mtcars$cyl, dnn=“N of cylinders”)
N of cylinders
4 6 8
11 7 14
를 얻는다.
교차표는 행에 사용할 벡터와 열에 사용할 벡터를 순서대로 설정하여 얻을 수 있다. 실린더 수와 기어 단수에 대한 교차표를 얻어보면
> tabel(mtcars$cyl, mtcars$gear)
3 4 5
4 1 8 2
6 2 4 1
8 12 0 2
로 얻으며, 4기통에 3단 기어인 경우가 1대, 4단 기어인 경우가 8대 등의 결과를 확인할 수 있다. 앞의 경우와 같이 dnn을 설정하여 행과 열의 이름을 설정해보면
> table(mtcars$cyl, mtcars$gear, dnn=c(“N of cylinders”, “전진기어단수”))
전진기어단수
N of cylinders 3 4 5
4 1 8 2
6 2 4 1
8 12 0 2
로 행과 열의 이름이 설정됨을 알 수 있다.
도수분포표나 교차표와 같은 table 함수의 결과를 R 개체로 저장할 수 있고(이와 같은 개체는 table개체이며 is.table 함수로 table 개체인지 확인할 수 있다) table 함수의 결과를 입력으로 사용하는 함수가
몇가지 R에서 제공된다. 이들 함수는 table 함수의 결과물을 사용하여 좀 더 나은 형태의 표를 만들 수 있도록 해주며, 이를 소개하기 위해 먼저 위의 교차표를 mytbl이라는 이름으로 저장해보자.
> mytbl <- table(mtcars$cyl, mtcars$gear, dnn=c(“전진기어단수”, “N of cylinders”))
table 함수의 결과는 각 행이나 열의 빈도에 대한 합이 출력되지 않는다. 이를 추가하려면 addmargins 함수를
addmargins(A, margin = seq_along(dim(A)), FUN = sum, ...)
로 사용할 수 있다. 여기에서
· A: table 함수 등으로 얻은 table 개체의 이름을 설정하며
· margin: 숫자 1,2 등을 사용하여 행별 계산을 적용할지 열별 계산값을 얻을지 설정한다. 기본값은 행과 열 모두에 적용된다.
· FUN에는 각 행 또는 열별 계산에 사용할 함수의 이름을 설정한다. 기본값은 sum이므로 행과 열별의 합이 만들어진다. 만일 각 행별 열별 평균을 얻으려면 sum 대신 mean을 사용한다.
앞에서 저장한 mytbl의 행별 열별 합을 추가해보면
> addmargins(mytbl)
N of cylinders
전진기어단수 3 4 5 Sum
4 1 8 2 11
6 2 4 1 7
8 12 0 2 14
Sum 15 12 5 32
를 얻는다.
도수분포표나 교차표에서 각 칸에 대한 절대빈도가 아닌 상대빈도(비율)을 얻고자 할 때가 있는데 이때 사용할 수 있는 함수로 prop.table이 있다. 이 함수는
prop.table(x, margin = NULL)
로 사용하며 x에는 table 개체의 이름을 설정하고, margin에는 행에 대한 상대빈도인지, 열에 대한 상대빈도인지, 아니면 전체에 대한 상대빈도인지 설정하며 기본값은 전체애 대한 상대빈도이다.
> addmargins( prop.table(mytbl) )
N of cylinders
전진기어단수 3 4 5 Sum
4 0.03125 0.25000 0.06250 0.34375
6 0.06250 0.12500 0.03125 0.21875
8 0.37500 0.00000 0.06250 0.43750
Sum 0.46875 0.37500 0.15625 1.00000
mytbl의 결과를 백분율(%)로 표시하면서 소숫점 이하 두 자리만 표시하고자 한다면 위의 결과에 100을 곱하고 round 함수에 digit값에 2를 설정한다. 즉,
> round( addmargins( prop.table(mytbl) )*100, 2)
N of cylinders
전진기어단수 3 4 5 Sum
4 3.12 25.00 6.25 34.38
6 6.25 12.50 3.12 21.88
8 37.50 0.00 6.25 43.75
Sum 46.88 37.50 15.62 100.00
를 얻을 수 있다.
margin에 1을 설정하여 행별 상대도수를 구하고, 이들의 열별 합을 addmargins 함수로 구하여 보면
> addmargins(prop.table(mytbl, margin=1), margin=2)
N of cylinders
전진기어단수 3 4 5 Sum
4 0.09090909 0.72727273 0.18181818 1.00000000
6 0.28571429 0.57142857 0.14285714 1.00000000
8 0.85714286 0.00000000 0.14285714 1.00000000
를 얻는다.

그래프
R은 데이터 시각화를 위한 강력한 그래픽을 제공한다. 그 중 가장 기초적인 것을 몇가지 소개하기로 한다.
5.1 원그래프와 막대그래프
원그래프는 범주형 자료의 빈도를 원의 각에 비례하도록 그린 그림으로 R에서 pie 함수를 사용하여 그릴 수 있다. 막대그래프는 범주의 빈도를 기둥의 높이로 그린 그림으로 barplot 함수를 사용하여 그린다. 이
두 함수는
pie(x, labels = names(x), density = NULL, angle = 45, col = NULL, ...)
및
barplot(height, names.arg = NULL, legend.text = NULL, beside = FALSE,horiz = FALSE, density = NULL, angle = 45, col = NULL, ...)
로 사용한다. 매개변수는
· x와 height: 원그래프나 막대그래프를 그리기 위한 빈도수가 저장된 벡터나 table 개체의 이름
· labels: 원그래프의 각 부채꼴의 이름을 문자열로 저장한 벡터의 이름
· density: 원그래프나 막대그래프의 각 부채꼴 및 기둥의 내부를 색을 칠하지 않고 빗금을 그릴 때 빗금의 밀도(인치당 빗금의 수)
· angle: 빗금을 그릴 때 빗금의 각도
· col: 각 부채꼴 및 기둥의 내부 또는 빗금의 색깔
· names.arg: 막대그래프의 가로축에 사용할 이름을 저장한 벡터
· legend.text: 막대그래프에서 범주를 만들 때 범주에 사용할 문자열
· beside: 누적막대그래프를 그릴지 좌우(또는 상하)로 기둥을 분리할지 설정
· horiz: 기둥을 가로로 그릴지 설정한다.
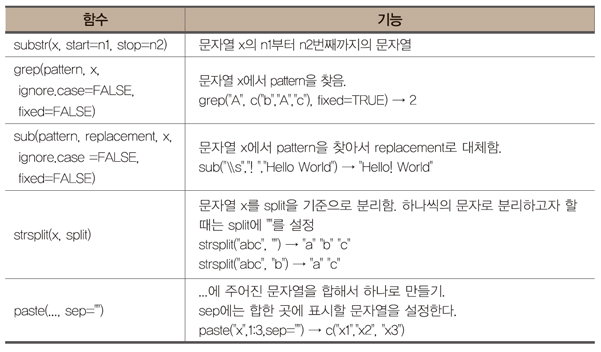
pie 함수는 빈도수를 저장한 벡터나 table 함수의 개체를 입력으로 받으므로
> pie(mtcars$cyl)
명령으로 얻은 원그래프는 원하는 그래프가 아닐 수 있다. 이 명령의 결과는 다음 그림의 왼쪽의 그림으로 R은 mtcars$cyl의 각각의 값이 어떤 범주의 빈도라고 생각하고(이 경우 빈도값은 4, 6 또는 8) 자료의
수가 32개가 있으므로 범주의 수가 32개가 있다고 보고 그림을 그린 것이다. 따라서 데이터 프레임의 원시자료의 경우 table 함수 등을 이용하여 빈도수를 얻은 다음 이 결과를 pie 함수의 매개변수로 사용하여
그려야 한다. 즉,
> pie(table(mtcars$cyl))
와 같이 사용하여야 한다. 이 명령의 결과는 다음 그림의 오른쪽 원그래프이다.
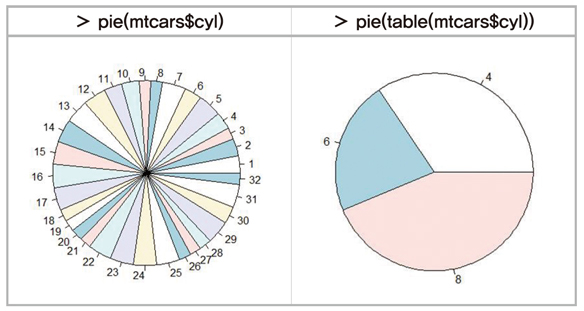
이번엔 각 부채꼴의 이름을 labels에 설정해보자. 이 이름은 4 기통, 6 기통 및 8 기통이므로 paste(c(4,6,8), “기통”, sep=””)로 이 문자열을 만들 수 있다. 따라서
> pie(table(mtcars$cyl), labels=paste(4,6,8), “기통”, sep=” ”), col=5:7)
로 명령할 수 있으며(사용한 색깔은 R의 기본 palette의 색깔이며 이에 대해서는 전호에서 소개하였다) 이 명령의 결과는 다음 그림의 왼쪽 원그래프이다. 이번엔 angle과 density를 설정하여 빗금을 그려보자.
빗금의 각도는 0˚,45˚,90˚로 설정하고 빗금의 밀도는 모두 8로 다음
> pie(table(mtcars$cyl), labels=paste(c(4,6,8), “기통”, sep=” “), angle=c(0, 45, 90), density=8, col=2:4)
과 같이 설정하면 다음 그림의 오른쪽 원그래프를 얻는다.
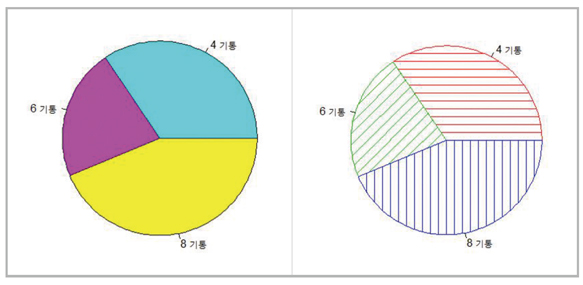
실린더 수에 대한 막대그래프는
> barplot(table(mtcars$cyl), names=paste(c(4,6,8), “기통”, sep=” “), col=5:7)
로 얻을 수 있다. names.arg와 col에는 앞의 pie 함수에서와 같은 값을 사용하였다. R 함수는 서로 구분할 수 있을 정도까지만 속성을 입력해도 되므로 names.arg 대신에 names까지만 입력하여도 된다. 이번엔
horiz에 T를 설정하여 같은 막대그래프를 가로로 그려보려면
> barplot(table(mtcars$cyl), names=paste(c(4,6,8), ”기통”, sep=” “), col=5:7, horiz=T)
를 사용할 수 있다. 위의 두 명령의 결과는 다음의 그림과 같다.
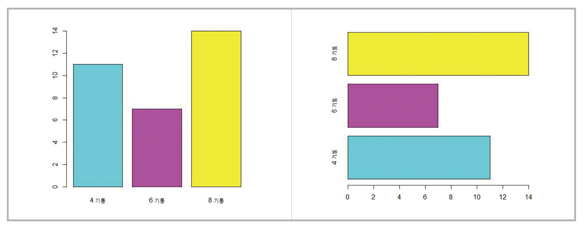
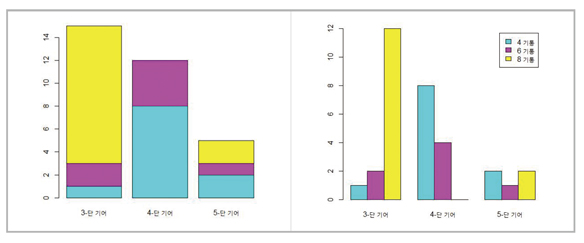
막대그래프는 한 변수 뿐 아니라 두 변수에 대해서도 그릴 수 있다. 예를 들어 기어단수별 실린더수에 대한 막대그래프를 그려보자. 먼저 x축의 이름에 사용할 문자열 벡터를
> x.mark <- paste(c(3,4,5), “단 기어”, sep=“-”)
로 만든 후 , 앞에서 본 mytbl을 사용하여 막대그래프를 그려보려면
>barplot(mytbl, names=x.mark, col=5:7)
를 사용할 수 있다. 이 결과는 다음 그림의 왼쪽 그림인데 서로 다른 색이 무엇을 의미하는지 명확하지 않으므로 범례를 추가할 필요가 있다. 범례를 추가하기 위해 범례에 사용할 문자열을 앞에서 본 것과 같은
방법으로
> l.text <- paste(c(4,6,8, “기통”, sep=” “)
를 만들고 이를 legend.text에 지정한다. 추가로 beside에 T를 설정하여 누적막대가 아닌 좌유 막대를 얻어보기로 한다. 즉,
> barplot(mytbl, names=x.mark, col=5:7, beside=T, legend.text=l.text)
를 명령한다. 이 명령의 결과는 다음 그림의 오른쪽 막대그래프이다.
5.2 상자그림과 히스토그램
상자그림이나 히스토그램은 자료가 연속형일 때 사용하는 그래프이다. 상자그림은 자료의 최소, 25% 백분위수, 50% 백분위수, 75% 백분위수 및 최댓값을 사용하여 중간의 50%는 상자로 표현하고 큰 쪽과 작은 쪽
25%씩은 선으로 연결한 그림을 말한다. 히스토그램은 연속인 속성을 가지는 자료에서 일정구간에 포함되는 자료의 빈도를 막대그래프와 같이 사각형의 높이로 표현한다. 기본 속성이 연속이므로 기둥을 분리하지
않는 특징이 있다. 이 둘은 각각 다음의 boxplot 및 hist 함수를 사용하여 만든다.
boxplot(x, ...)
boxplot(formula, data = NULL, ...)
hist(x, freq = NULL, plot = TRUE, labels = FALSE, ...)
위에서
· x는 상자그림이나 히스토그램을 그릴 자료가 저장된 벡터의 이름을 설정한다.
· formula에는 y ~ x 형태로 설정하여 x의 각 값에 따른 y의 히스토그램을 그리도록 설정한다. 예를 들어 성별(gender)에 따른 키(height)의 상자그림을 각각 그리려면 height ~ gender로 설정한다.
· data: formula에 사용한 변수의 이름이 특정 데이터 프레임의 변수일 경우 데이터 프레임의 이름을 설정한다.
· freq: 히스토그램의 높이를 절대빈도로 할지 상대빈도로 할지 설정한다. 절대빈도인 경우 TRUE(기본값), 상대빈도인 경우 FALSE를 설정한다.
· plot: 실제 히스토그램을 그릴지 설정한다. 기본값은 TRUE이며 FALSE로 설정될 경우 히스토그램을 그리기 위해 계산된 여러 가지 값만 출력하고 히스토그램은 그리지 않는다.
· labels: 히스토그램의 각 기둥에 문자열을 추가하고자 할 때 문자열을 설정한다.
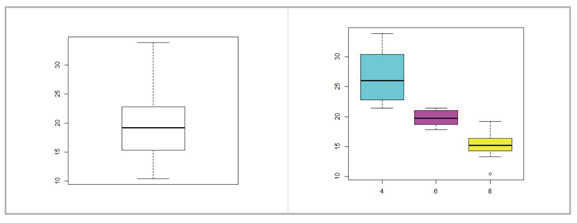
mtcars 자료를 사용하며 연비(1갤런당 주행거리) mpg에 대한 상자그림을 그려보자.
> boxplot(mtcars$mpg)
명령으로 기본 상자그림을 그릴 수 있으며 결과는 다음 그림의 왼쪽 그림이다. 이 그림에서 최솟값은 10 근처, 최댓값은 35 부근임을 알 수 있으며 약 19인 중앙값을 중심으로 50%의 자료가 15부터 23 사이에
위치함을 이해할 수 있다. 정확한 이 값들은 앞에서 소개한 quantile 함수나 summary 함수로 얻을 수 있다.
상자그림은 하나의 상자그림으로 분포의 형태를 파악하기 위해서도 많이 사용하지만 둘 이상의 그룹에 따른 분포의 비교를 위해 사용하는 경우도 많다. 예를 들어 실린더 개수에 따라 연비가 달라지는지
알아보려면
> boxplot(mpg ~cyl, data=mtcars, col=5:7)
와 같은 명령으로 실린더 개수별 mpg의 상자그림을 그릴 수 있다. 결과는 다음 그림의 오른쪽에 만들어진 세 개의 상자그림이며 실린더의 수가 많은 경우에 연비가 낮아짐을 확인할 수 있으며, 더불어 4기통
엔진의 경우 연비의 변동성이 6기통이나 8기통에 비해 큼을 알 수 있다.
이번에는 mtcars에서 연비의 분포를 알아보기 위한 히스토그램을 그리는 방법에 대해서 알아보자. 기본적인 히스토그램은
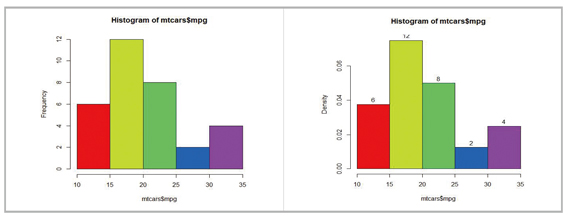
> hist(mtcars$mpg, col=rainbow(5))
명령으로 그릴 수 있으며 col(색깔설정)에 사용한 rainbow 함수는 무지개색을 얻는 함수로 지난 호에서 살펴본 것이다. 이 명령의 결과는 다음 그림의 왼쪽 창에 얻어진다. hist 함수는 히스토그램을 그리기
위한 여러가지 값을 출력으로 얻을 수 있는데(자세한 것은 help(hist) 명령으로 확인) 그 중 하나가 count로 각 구간별 빈도수이다. 이번에 히스토그램을 그리되 기둥의 높이는 상대도수로 하고, 각 기둥에
구간별 빈도수를 입력하는 방법을 생각해보자. 먼저
> h.data <- hist(mtcars$mpg, plot=F)
명령으로 히스토그램은 그리지 않고, 계산값만 얻는다. 이 명령에서 plot=F이므로 히스토그램을 그리지 않는다. 이제 다시 한 번 hist 명령을 사용하되 옵션에 freq=F로 labels에는 각 구간별 빈도수인 count를
문자열로 변경(as.character 함수)하여 다음
> hist(mtcars$mpg, col=rainbow(5), freq=F, labels=as.character(h.data$count))
과 같이 설정한다. 이 설정의 결과는 다음 그림의 오른쪽 히스토그램이다.